
语音驱动说话人表情渲染
我的毕业课题项目,实现基于物理真实感的语音驱动说话人表情生成,包括语音驱动生成表情与头发渲染两个方向。
随着硬件与虚拟现实设备的快速发展,人们说话时的面部表情、唇部动作,甚至是头部与肢体的动作都可以帮助听众理解对话内容。视觉和听觉的双模态信息融合的交互方式,不仅能提高用户对内容的理解度,还能提供一种更为准确的交互体验,提高歌唱的艺术性和观赏度。语音驱动嘴型和面部动画生成技术可以让开发者快速构建一些基于数字人的应用,如虚拟主持人、虚拟客服和虚拟教师等。除了能提供更友好的人机交互方式之外,该技术在感知研究、声音辅助学习等方面具有重要应用价值,同时,能够在游戏和电影特效等娱乐化方面降低作品制作成本。 语音驱动嘴型与面部动画生成技术,可以让用户输入文本或语音,通过某种规则或者深度学习算法生成对应的虚拟形象的表情系数,从而完成虚拟形象的口型和面部表情的精准驱动。但是当前的技术或多或少都有一定的缺陷,如:
本课题旨在调研当下先进的语音驱动三维人脸技术,进一步研究和优化训练模型,采用深度学习的方式在现有工程的基础上进行完善,力求降低以上缺陷问题的影响。这其中需要主要参考以下论文的内容:
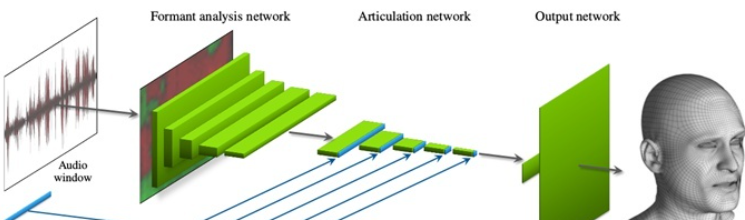
早期提出的一种采用端到端的卷积网络,从输入的音频在直接推断出人脸表情变化对应的顶点位置的偏移量实现音频驱动人脸表情动画的效果。
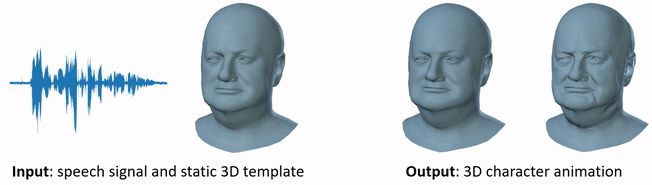
本篇论文主要提出了使用一种独特的4D人脸数据集进行训练,包括以60fps帧速率捕捉到的4D扫描以及12名说话者的同期声作为基础的训练模板。同时还提出了VOCA模型,一种可以使用任意语言信号作为输入(即使不是英语也可以),然后将大量面目转换为逼真的动图。并且VOCA是已知唯一的可以做到关联与身份相关的面部姿势(包括头部、下巴和眼球旋转)来实现说话风格的改变,并且还可以适用于训练集中未出现过的人物形象,这一优势可以在游戏虚拟任务中明显体现。
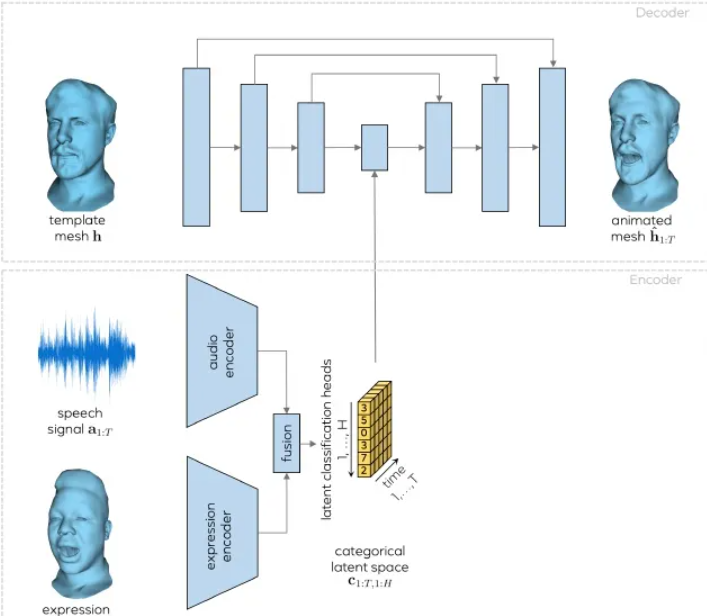
这篇论文提出了一种采用自回归的方式来用基于模型训练的过去数据点来预测新数据点,也就是利用时序信息来进一步进行高真实感人脸动画的合成。同时由于VOCA并没有对面部表情的所有方面进行编码,因此音频驱动的面部动画问题试图学习一对多的映射,每个输入对应有多个输出,这样可以实现过渡平滑的结果,在面部区域只有微弱不相关的音频信号。因此需要涉及到一种新的面部动画分类隐空间,这个空间可以来解耦声音相关和不相关的信息。
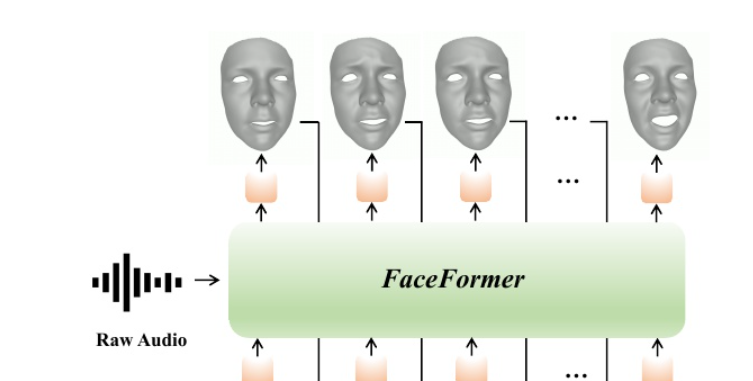
同上论文,驱动模型与MeshTalk类似,采用自回归的思想来对输入的音频和中性的3D人脸mesh生成一段带嘴型运动的3D人脸动画,但是生成的效果更佳。可以对比两篇代码实现尝试学习优化思路。

最后还可以参考开源的项目Voice2Face学习具体的代码实现。

本课题还将在基于语音驱动生成三维人脸情绪动画的基础上,尝试对人脸进行人脸毛发和眼睛的真实渲染。在虚拟游戏,影视作品等应用场景中,虚拟人物的占比越来越多而且已经成为一个体系,渲染和优化的时候都会为角色量身定制一套真实感渲染的方案。甚至为了表现角色使其更加逼真,会为展示在大厅的角色单独做一套效果和资源,因此这就要求需要先进的技术来优化实现人物毛发与眼睛的真实渲染。
对于头发的渲染我们可以从头发的模型、头发的贴图、头发的shader等展开分别进行优化处理。对于头发渲染会面临一下结果难题:
为了优化解决以上问题,我们首先可以再模型头发模型方面进行选择尝试减少开销,当下比较常见的方案有
由于头发具有各向异性材质的特点,因此人的头发会有一种”天使环“的效果,即各向异性高光,一般呈现环状出现在头顶。我们可以将头发中的每一个发丝都是为一个非常细长的圆柱体,那么头发整体的高光就是这每一根圆柱形发丝高光组成的,因此为了为了表现每一根都发的高光使用贴图是不可或缺的,包括:漫反射贴图、法线贴图、环境光遮蔽贴图、偏移贴图、透明贴图等。
对于头发的渲染还衍生了不同的渲染模型,以下几种模型复杂程度逐渐递增,真实感效果也更优秀。
参考文献:
这是一种基于经验的着色模型,即并不能完全的着色物理正确,但是对于开销小的情况下仍可以得到不错的真实感效果。在这个模型中,头发纤维被抽象为一个不透明的圆柱体,不能够透射和产生内部反射,因此这种模型不能表现一些肉眼观察到的头发效果,同时能量也是不守恒的,在这个模型中光照主要是Diffuse(使用Lambert)和Specular(Phong)。由于该模型将头发看成不透明的圆柱体,因此不能模拟光纤穿透头发或者在头发中传播的情况,这就导致其并不能模拟出背光或者二次高光的效果。
参考文献:
这种模型与前者区别就是基于物理的,而不再是基于经验的。该模型通过将头发纤维抽象为一个透明的椭圆柱体,可以模拟头发丝之间的散射现象。